Powering modern enterprises











Scale with
Confidence.
We deploy private, secure AI infrastructure for high-volume operations. Vendor matching, API integrations, and on-premise deployment.
- Custom Voice Models
- SOC2 & GDPR Compliance
- High-Volume Throughput
News and announcements from Next Big App

We Had 10 Years for Digital Transformation. We Have 10 Months for AI.
The overlooked AI shift costing you sales. Competitors make 5,000 calls while your team makes 30. Unlock this breakthrough framework to scale now.
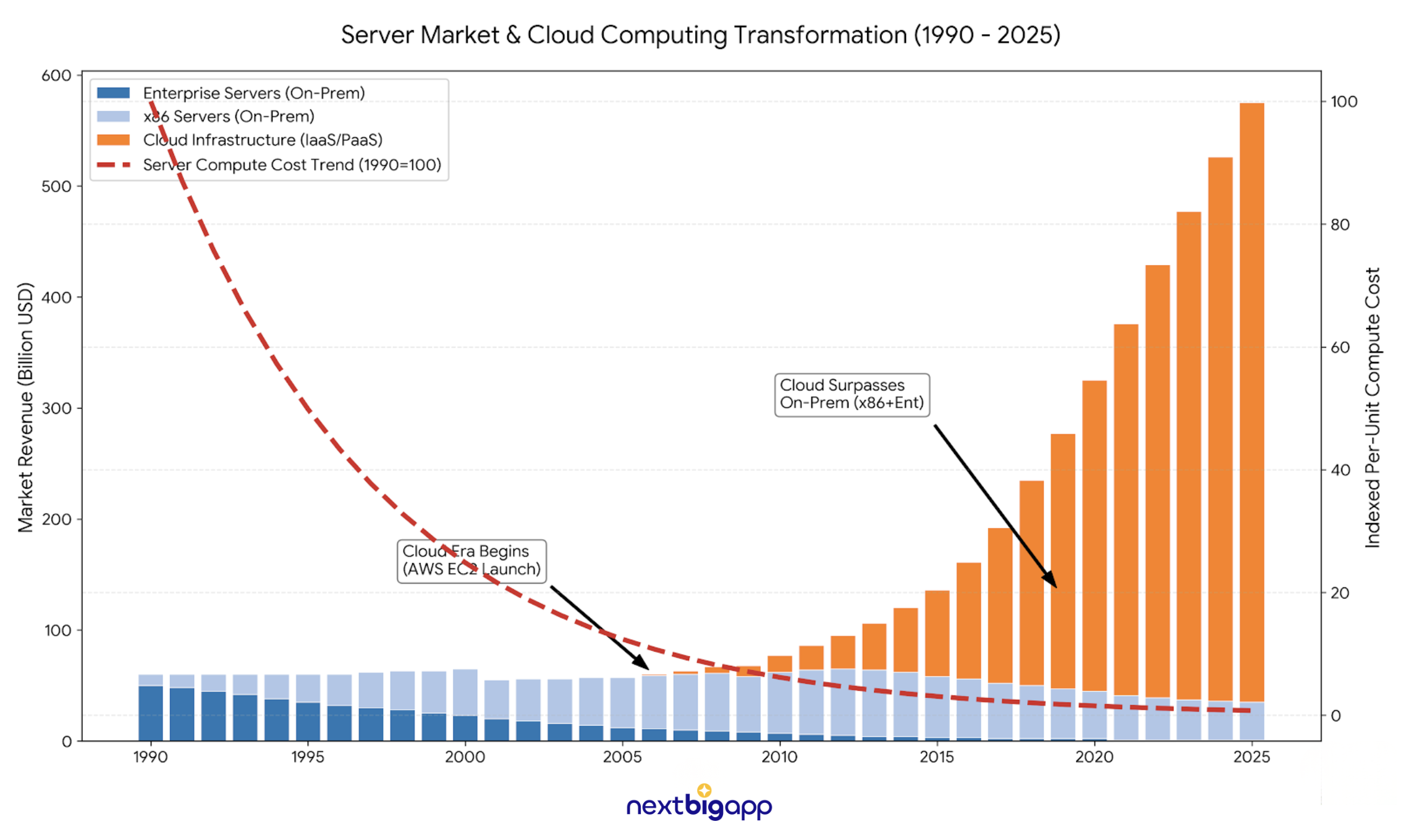
The Jevons Paradox: AI Isn't Killing Software, It's Turning It Into Infrastructure
Discover why plummeting software costs won't kill SaaS, it will explode the market. Unlock the secret of \"Invisible SaaS\" and how to profit as code ...
Issue #100 - 700 Days, 300,000 Minds, One Ritual
A blank screen and 100 weeks of showing up. Discover the quiet lessons learned while building in public and how they can help you in your own founder ...
The Next Chapter: Scaling Global AI
In December 2025, Next Big App entered a new era of growth through a strategic investment from the İş Portföy - Webrazzi Startup-1 Venture Capital Investment Fund.
This partnership accelerates our mission to build the AI Operating System for small businesses. It is a powerful validation of our technology and its ability to solve the most critical challenge in business: scaling sales and customer experience without increasing headcount.
Institutional Trust
Backed by Turkey’s leading financial and tech ecosystems.
Proven Impact
Actively powering sales for industry leaders like Eczacıbaşı, İş Bankası, Vitra, BigChefs, and İdeasoft.
Global Reach
Serving a community of 300,000+ founders as we expand aggressively into the US and UK markets.
We aren't just building apps; we are building the future of how work gets done.
The Growth
Ritual.
Join 300k+ founders receiving our weekly deep dives on scale, automation, and AI infrastructure. No fluff, just leverage.
Read by teams at Stripe, Monzo, and YC.
The $10M Solopreneur Stack
How a one-person unicorn generates $10M ARR without employees.
Vertical AI Moats
Why generalist wrappers are dying and vertical agents are winning.
Kill Your SDR Team (Kindly)
Transitioning from human cold callers to AI voice agents.
Programmatic SEO Blueprint
Generating 10,000 landing pages that actually rank using Gemini 2.5.
Automating Trust at Scale
Using AI to personalize outreach without losing the human touch.