Yeni Anlam Kazandıran İçerik > Bol İçerik
Son 20 yıldır, çeşitli dijital ürünlerde karşımıza çıkan büyüme fırsatlarından biri olarak hep taktiksel SEO sunuldu. Çoğu işe yarayan, bazıları da hurafe…
Pazarlama ekipleri bu döngü içerisinde içerik ve pazarlamayı benzer “tiyo”larla büyütmenin peşinde oldu. Dijitalde çok tık istiyorsan çözümü hep anahtar kelimeler vs arandı.
Diğer taraftan, eğer 10 makale bize 10.000 ziyaretçi getiriyorsa, yüz makale kesin 100.000 getirir diye düz bir mantıkla yaklaşıldı içerik stratejilerine.
Ama, yapay zeka temelli (arama değil) cevap motorları dünyasında artık bu doğrusal mantığın tamamen bittiğini görüyoruz.
2026 yılında, içerik üretim hızını artırmak bize otorite kazandırmıyor; sadece bütçemizi eritiyor.
Google, trafiği web sitelerine yönlendiren geleneksel bir arama motoru olmaktan çıkıp, artık yapay zeka özetleriyle (Search Generative Experience) çalışan bir “Cevap Motoru”na dönüştü.
“Sıfır tıklamalı aramalar” artık standart hale gelmişken, eski usul, seri üretim içerik fabrikaları çok da bir fayda sağlamıyor.
Algoritma artık ne kadar çok kelime yayınladığımıza bakmıyor. Bize “Bilgi Kazanımı” (Information Gain) ve makinelerin okuyabileceği yapısal veriler (Machine-Readable Structure) için ödül veriyor.
Eğer büyüme stratejimiz hala internetteki mevcut bilgileri evirip çevirerek seri üretim makaleler yazmak üzerine kuruluysa, organik trafiğimiz düşmeye devam edecek demektir.
RAG Filtresi: “Daha Fazla” İçerik Neden Artık “Daha İyi” Değil?
Google’ın SGE’si arama sonuçları sayfasında (SERP) bir özet oluştururken RAG (Arama-Destekli Üretim) altyapısına dayanıyor.
Yapay zeka sadece bir sonraki kelimeyi tahmin etmeye çalışmıyor; güvenilir indeks kaynaklarından verileri çekiyor, belirli metin bloklarını ayıklıyor ve bunları doğrudan bir cevap haline getiriyor.
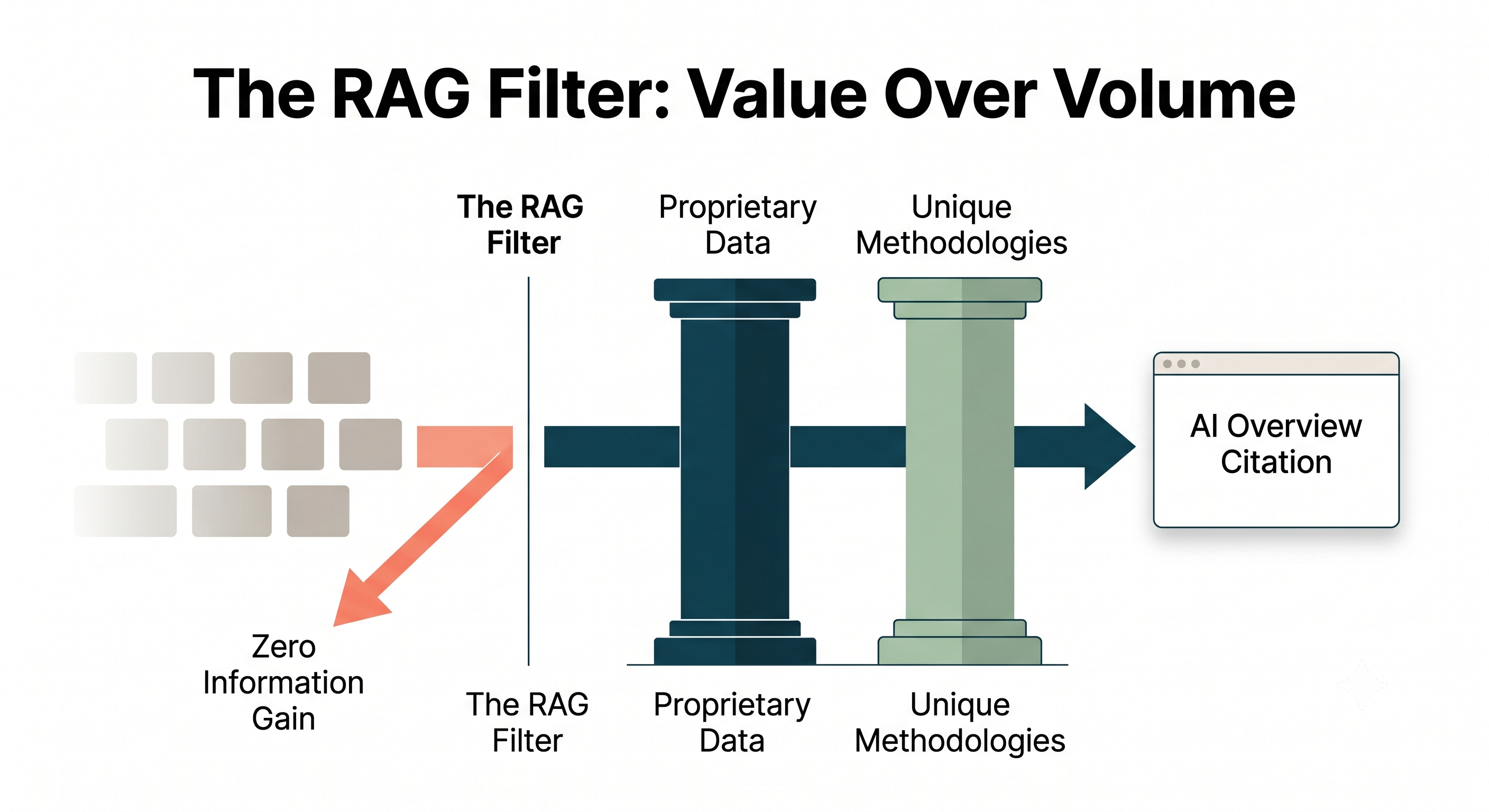
Bu veri getirme (retrieval) aşamasında Google, katı bir algoritmik filtre uyguluyor: Bilgi Kazanımı (Information Gain) kontrolü**.**
Eğer makalemiz ilk 10 arama sonucundaki kavramları tekrar edip özetlemekten başka bir işe yaramıyorsa, Bilgi Kazanımı skorumuz sıfıra yakın oluyor.
RAG mekanizmasının aynı fikrin on birinci versiyonuna ihtiyacı yok yani.
Yapay zeka destekli arama dünyasında kaynak gösterilmek istiyorsak, içerik stratejimizi hacim odaklı olmaktan çıkarmak lazım;
-
Özgün Veri (Proprietary Data): Başka bir yerin internetten kazıyamayacağı ya da taklit edemeyeceği birinci taraf anketler, platform içi metrikler ve orijinal vaka analizleri (case study).
-
Özgün Metodolojiler: Liderlik ekibimize özel, tescilli çerçeveler (framework) ve isimlendirilmiş fikri mülkiyetler. Bunları botlara (crawler) “Quotation” şeması (schema) üzerinden açıkça beslememiz lazım.
Anahtar Kelimelerden Anlamsal Yapılara
Sektörün dışındakiler SEO’yu bir metin yazarlığı işi sanıyor. İşin mutfağındakiler ise aslında bunun bir veri tabanı mimarisi problemi olduğunu bilir.
Geleneksel içerik fabrikaları, anahtar kelime yoğunluğuna (keyword density) odaklanır. Ama Gemini ve gelişmiş LLM modellerinin, anahtar kelime doldurmayı artık (keyword stuffing) tamamen görmezden geldiğini biliyoruz.
Önce şunu çok iyi anlamak lazım. Artık arama motorları tek bir sebep için İnternet’i tarıyor;
Kategorilendirebileceğim, başka olgu, olay, marka, insan ya da varlıklarla yeni anlam ilişkileri kurabileceğim bir bilgi var mı bu gezdiğim sitede**?**
Yapay zeka, metni “varlıklar” yani şirketler, ürünler veya belirli metodolojiler gibi benzersiz, tanımlanabilir kavramları bulmak için okuyor.
Sonra da bunların küresel Bilgi Grafiğinde (Knowledge Graph) birbirleriyle nasıl ilişkilendiğini haritalandırıyor.
Eğer markamız ve sunduğumuz çözümler birbirine bağlı “Düğümler” (Nodes) olarak açıkça modellenmemişse, yapay zekanın otoritemizi anlamlandırması bir hayli zordur.
Mesela Next Big App’te herhangi bir içerik yayınlamadan önce, Neo4j ya da ArcadeDB gibi bir graph database altyapısı kullanarak haritalandırmaya ve daha anlamlı bize özgü hale getirmeye çalışıyoruz.
Bu sayede bir yapay zeka motorunun marka ekosistemimizi tam olarak nasıl yorumlayacağını önceden simüle edebiliyoruz.
Güçlü bir içerik stratejisine birbirinden bağımsız anahtar kelimelerle başlamamak lazım. Arama motorlarının ve yapay zeka sistemlerinin markamızın pazardaki rolünü anlamasını sağlayacak net bir bilgi yapısıyla yola çıkmalı.
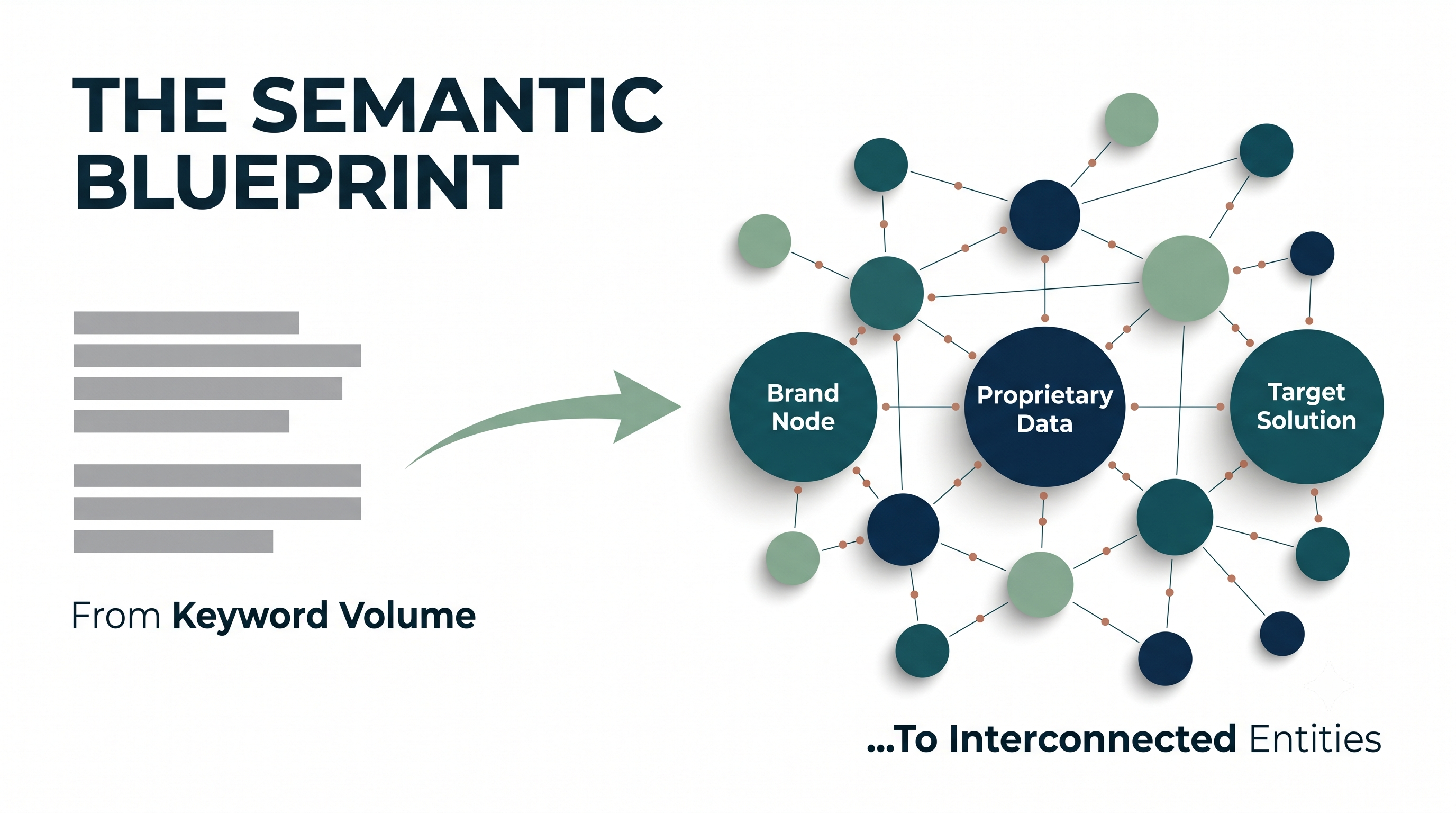
Temel akış şu şekilde ilerliyor:
-
Şirketiniz özgün bir çerçeve geliştirir: Bu, markamızın kategorideki diğer şirketler gibi görünmesini engeller ve bize benzersiz bir bakış açısı kazandırır.
-
Bu çerçeve müşterinin yaşadığı spesifik bir soruna değinir: İçeriğimiz, hedef kitlemizin neyle mücadele ettiğini, bunun neden önemli olduğunu ve mevcut çözümlerin neden yetersiz kaldığını net bir şekilde açıklamalıdır.
-
Müşterinin yaşadığı sorun, doğal bir şekilde hedef çözüme bağlanır: Ürünümüz veya hizmetimiz, zorlama bir satış stratejisi gibi değil, problemin mantıklı ve doğal bir çözümü olarak konumlanmalıdır.
-
Bu durum anlamsal bir zincir (semantic chain) oluşturur: Şirket → Çerçeve → Sorun → Çözüm
Bu durum çok önemli, çünkü yapay zeka arama sistemleri sadece anahtar kelime eşleşmelerine bakmıyor. Dediğimiz gibi varlıklar, kavramlar, problemler ve cevaplar arasındaki net ilişkilere odaklanıyor.
İçeriklerimizde metodolojimizi tekrar tekrar anlatıp gerçek müşteri sorunlarına uyguladığımızda ve bunu somut bir çözüme bağladığımızda, markamızın anlaşılması, kaynak gösterilmesi ve önerilmesi çok daha kolaylaşır.
Pratikte bu durum, sadece trafik çekmek için makale yayınlamadığımız anlamına geliyor.
Şirketimizin etrafında, fark edilebilir bir otorite haritası inşa etmeyi hedefliyoruz.
Zamanla markamız, belirli bir problemi çözmenin kendine has yöntemiyle özdeşleşir. Site mimarimiz bu temiz ve çelişkisiz anlamsal ağı (semantic web) yansıttığında, Google botları bağlamsal alakamızı anında analiz edebilir.
Yapısal Süreçleri Otomatikleştirmek
Arama motoru verilerimizi anında sistemine alamıyorsa, şirket içi veri yapımızı haritalandırmanın hiçbir anlamı kalmaz.
İçerik evrenimizi yapay zeka botlarının ana diline çevirmemiz işi çok kolaylaştırır.
Yani JSON-LD (Schema Yapılandırılmış Veri) formatına.
Bu kodu manuel olarak yazmak ciddi operasyonel bir zorluk, evet. Biz bunun yerine, süreci dinamik ve ölçeklenebilir şekilde yönetmek için API entegrasyonlarına sahip LLM destekli otomasyon hatları kullanıyoruz.
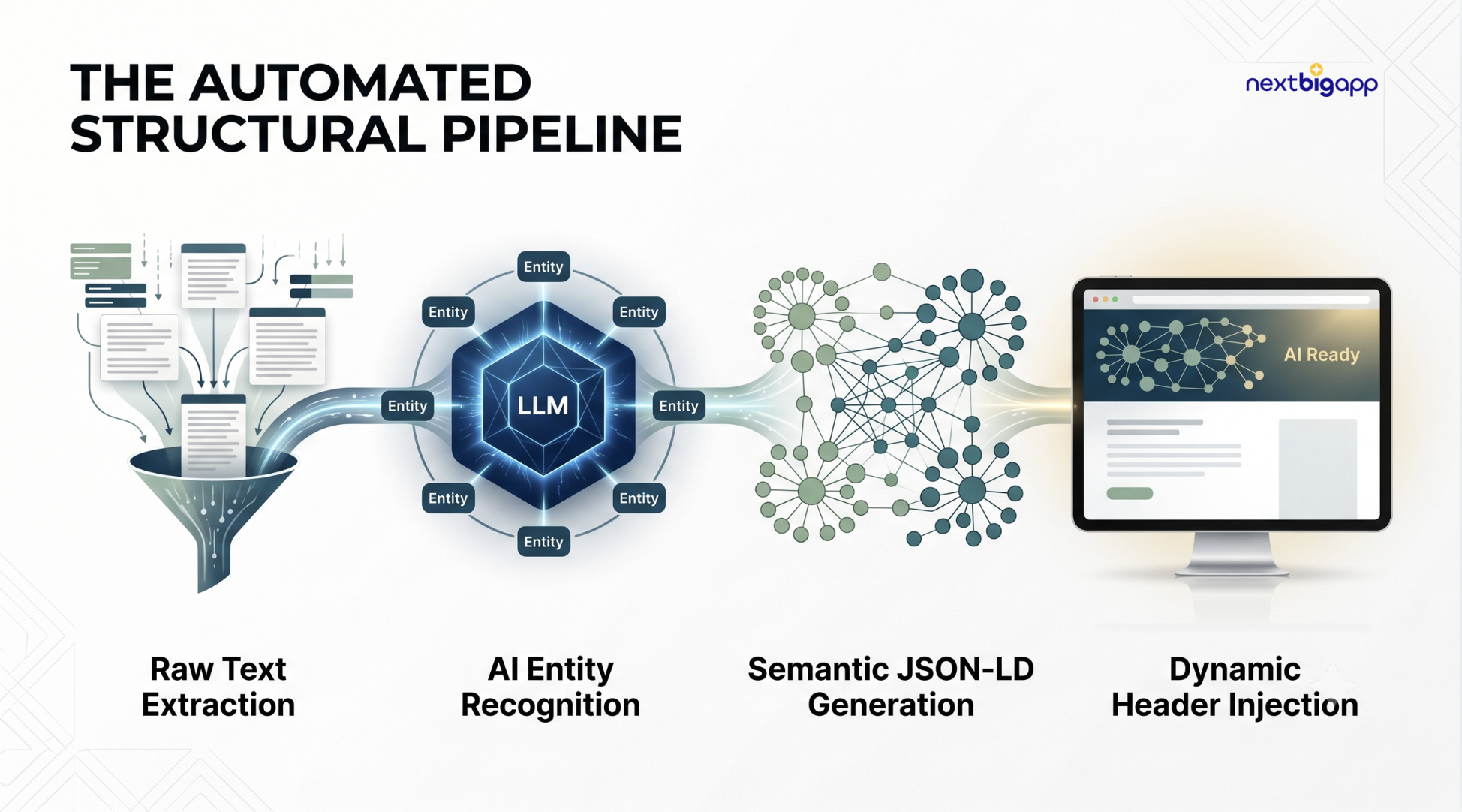
İzlediğimiz İş Akışı:
-
Veri Çıkarma: Yapısal ve veri odaklı bir makale yayınlandığı an, bir Python betiği (script) ham metni API aracılığıyla bir LLM’e gönderir.
-
Varlık Tanımlama (Entity Recognition): Model, ana kavramları, şirket içi uzmanları ve ürün ilişkilerini ayrıştırmak için “Adlandırılmış Varlık Tanıma” (NER) işlemini gerçekleştirir.
-
Anlamsal İşleme: LLM, şirket içi varlıklarımızı
sameAsetiketlerini kullanarak doğrudan otoriter düğümlerle eşleştiren, detaylı ve iç içe geçmiş bir JSON-LD çıktısı üretir. -
Dinamik Entegrasyon (Dynamic Injection): Arka plan (backend) bu şema çıktısını sayfa başlığına (header) otomatik olarak ekler.
Örnek JSON
{
"@context": "https://schema.org",
"@type": "TechArticle",
"headline": "Overcoming the Volume Illusion",
"about": [
{
"@type": "Thing",
"name": "Knowledge Graph",
"sameAs": "https://en.wikipedia.org/wiki/Knowledge_Graph"
}
],
"mentions": [
{
"@type": "SoftwareApplication",
"name": "Neo4j",
"sameAs": "https://en.wikipedia.org/wiki/Neo4j"
}
]
}
İçeriği “Parçalanabilir” (Chunked) Şekilde Tasarlamak
Yapısal yapbozun son parçası, yapmaktan pek de hoşlanmayacağımız operasyonel bir fedakarlık gerektiriyor.
Bir yapay zeka motoru tarafından kaynak gösterilmek istiyorsak, içeriğimizi botların kolayca parçalayabileceği ve kullanıcının tıklamasına gerek kalmadan doğrudan arama sonuçlarında (SERP) sunabileceği şekilde biçimlendirmemiz gerekiyor.
Gösteriş amaçlı blog trafiği yerine, yapay zeka modellerindeki otoritemizi artırmaya odaklanmak lazım. LLM’ler verileri belirli vektör pencerelerinde (parçalar/chunks halinde) işler.
Eğer sayfa düzenimiz yoğun ve yapılandırılmamış düz metin duvarlarından oluşuyorsa, RAG mekanizması ana fikirlerimizi gözden kaçırır.
-
Hiyerarşik Başlıklar (H-Tags): H2 ve H3 başlıklarımızı doğrudan net sorular veya keskin ve kesin ifadeler olarak kurgulamalıyız.
-
Özet (TL;DR) Blokları: Her ana bölümün en üstüne 2-3 cümlelik çok kısa özet blokları yerleştirmeli. Bu sayede RAG döngüsüne, Yapay Zeka Özetleri (AI Overview) içinde doğrudan kırpıp kaynak gösterebileceği temiz ve optimize edilmiş bir metin bloğu sunmuş oluruz.
Stratejik Yeniden Yapılanma
Arama trafiği yakalamak için vasat kelimeleri seri üretimle yayma dönemi bitti.
Üretken Arama Optimizasyonu (GEO) çağında, ana metriğimiz artık arama hacmi değil; yapay zeka modelinin zihnindeki payımızdır.

İnternetin zaten bildiği şeyleri tekrarlayan içerik fabrikalarını geride bırakmak lazım.
Markamızın, konunun asıl otoritesi olduğunu kanıtlayan, son derece yapılandırılmış ve veri odaklı bir mimari kurmaya başlamalı.
Özet; Eğer yapay zeka modeli yapımızı tanımazsa, piyasa da işletmemizi tanımaz.
Sıradaki yazılar

Algoritma Çağında Çalışmak: Bir Sipariş İçin Sonsuz Kaydırma
Çin’de kuryelerin sürekli ekran kaydırması sosyal medya bağımlılığı değil, siparişi ilk kapmaya dayalı algoritmik bir geçim mücadelesi. Rekabet, emeği saniyeler
25 Haz 2026
Akıl Demokratikleşiyor: Şirketler AI Sistemlerini Yeniden Kurmalı
Şirketler tek bir AI modeli seçmek yerine işleri zorluk seviyesine göre katmanlamalı. Güçlü modelleri zor işlere, küçük modelleri rutin görevlere ayırmak maliye
25 Haz 2026
Küçük Bir Tenis Derdi, Büyük Bir Ürün Dersi
Scorebot, tenis maçlarında skor tutma derdini değil, oyuncunun oyundan kopma sorununu çözüyor. İyi ürünler de tam böyle doğar: küçük ama tekrar eden bir sürtünm
25 Haz 2026